上一篇介绍了DTCoreText怎样把HTML+CSS解析转换成NSAttributeString,本篇接着看看怎样把NSAttributeString渲染出来。
CoreText
先简单介绍下CoreText,CoreText是iOS/OSX里的文字渲染引擎,在iOS/OSX上看到的所有文字在底层都是由CoreText去渲染。
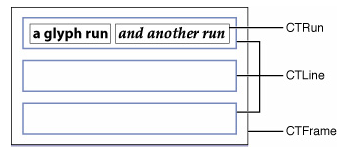
CoreText会把一行里连在一起相同属性的文字合在一起作为一个CTRun,每一行是一个CTLine,多行合在一起组成CTFrame。如上图,第一行的文字有两种样式,第一部分是加粗,第二部分是斜体,因为样式不同所以分成了两个CTRun,CTLine包含了这两个CTRun,CTFrame包含了所有CTLine。

一个NSAttributeString可以通过CoreText提供的方法生成CTFramesetter,CTFramesetter是用于创建CTFrame的工厂,给CTFramesetter一个CGPath,或者简单理解为给他一个框框,它就会通过它持有的CTTypesetter生成CTFrame,CTFrame生成时里面包含的CTLine和CTRun就全部生成好了,可以直接绘制到画布上。CTFrame/CTLine/CTRun都提供了渲染接口,但前两者是封装,最后实际都是调用到CTRun的渲染接口去绘制。
如果要用CoreText渲染NSAttributeString,可以简单生成CTFramesetter,再生成CTFrame,在UIView的drawRect方法里直接把CTFrame绘制到当前画布上:
- (void) drawRect:(CGRect)rect
{
UIBezierPath *path = [UIBezierPath bezierPathWithRect:CGRectMake(0, 0, 320, 400)];
CTFramesetterRef framesetter = CTFramesetterCreateWithAttributedString((__bridge CFAttributedStringRef)content);
CTFrame frame = CTFramesetterCreateFrame(framesetter,CFRangeMake(0, 0), [path CGPath] , NULL);
CGContextRef ctx = UIGraphicsGetCurrentContext();
CTFrameDraw(frame, ctx);
}
CoreText会按NSAttributeString里的样式属性把文字渲染出来。这种是最简单的粗粒度的渲染方式,但如果需要对文字渲染再做进一步处理,例如添加背景色等这些CoreText没有支持的属性,或者要在文字中间插入图片,就不能简单绘制CTFrame,需要逐行或逐个CTRun处理。
概览
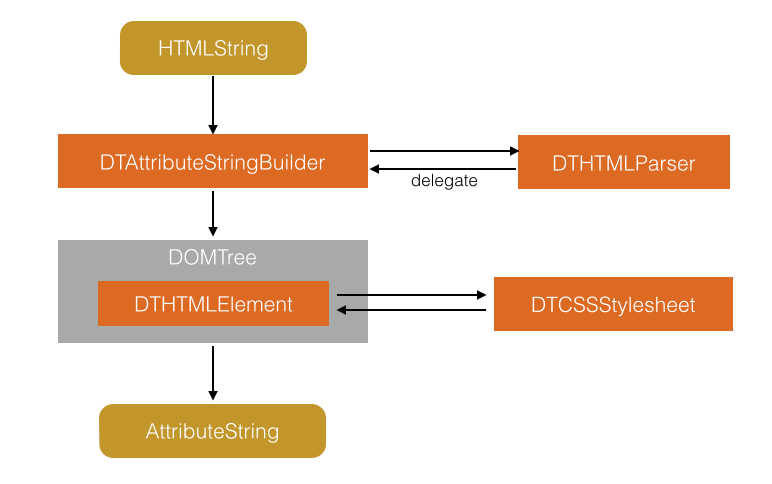
DTCoreText需要处理穿插在文字里的各类Attachment,并支持文字背景色,段缩进等CoreText不支持的属性,不能简单把NSAttributeString扔给CoreText渲染了事,需要做更细致的处理。DTCoreText分了几层,整体结构图:
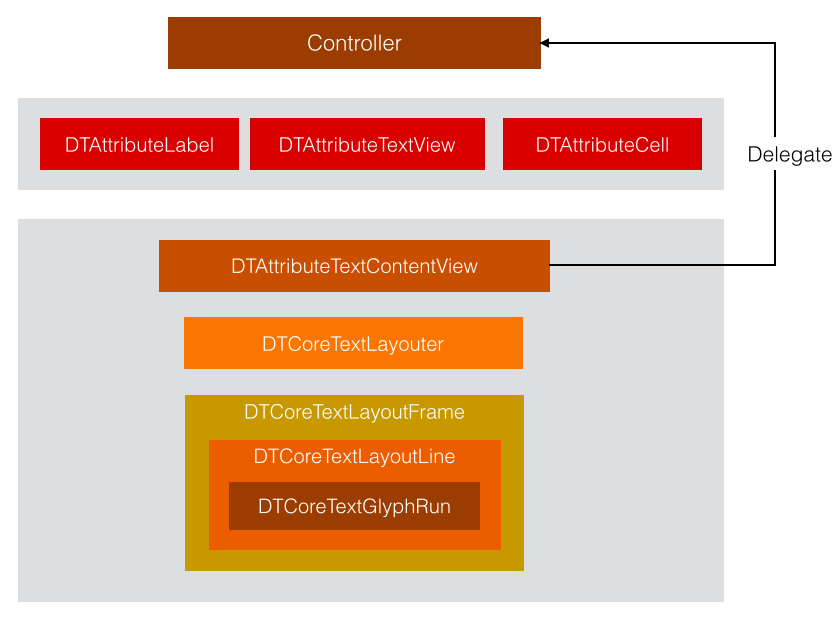
最上层是使用者,可以是Controller,例如项目里示例的DemoTextViewController,也可以是某视图类。接着是DTCoreText封装好的各个控件,自带的有Label,TextView和Cell,这些控件的文字渲染都由DTAttributedTextContentView负责,非文字部分例如图片/视频等元素会在上层使用者那里通过delegate传给DTAttributedTextContentView。DTCoreTextLayouter / DTCoreTextLayoutFrame / DTCoreTextLayoutLine / DTCoreTextGlyphRun这四个类分别对应CoreText里的CTFramesetter / CTFrame / CTLine / CTRun,模仿了CoreText的模式,功能和作用一样,只是在它们基础上添加了功能。接下来看看每一个类具体做了什么事情。
DTAttributedTextContentView
DTAttributedTextContentView继承自UIView,作为DTCoreTextLayoutFrame和上层控件的中间层,负责按需求绘制内容,大致做了以下几件事:
1.支持CATiledLayer分段渲染
把UIView的layerClass设为CATiledLayer就能实现分区域渲染,即只渲染显示在屏幕上的区域,类似那些地图APP的效果,主要用于像TextView这样可能内容很长的控件,避免一次性把全部内容渲染出来,只渲染能看到的部分,提高性能。使用CATiledLayer后,在-drawLayer:inContext:方法里用CGContextGetClipBoundingBox通过context取得当前显示的区域,DTCoreTextLayoutFrame只渲染这个区域的内容就行了。
2.生成DTCoreTextLayoutFrame并绘制
通过上层传进来的NSAttributeString生成DTCoreTextLayouter和DTCoreTextLayoutFrame,进行各种配置后用DTCoreTextLayoutFrame渲染文字到当前layer上,这些配置包括 是否显示图片链接/限定行数/断行规则等。
3.处理Attachment和Link
在-layoutSubviewsInRect:方法里遍历DTCoreTextLayoutFrame里的每一个DTCoreTextGlyphRun,找出有附件和链接的Run进行处理,附件包括图片/视频等,创建这些附件对应的view,把这些view按DTCoreTextGlyphRun计算好的位置添加到专门存放附件和链接的customViews上完事。
实际上这些附件view的创建是在上层使用者那里,DTAttributedTextContentView通过delegate把每个附件的内容和对应的frame传到上层生成相应的view再给回来,这样做估计是因为对附件的处理每个使用者的需求都不一样,不应该直接写死在底层,例如有些使用者要求图片需要点击后放大,视频需要用自己的控件等。
DTCoreTextLayouter
DTCoreTextLayouter负责生成和缓存DTCoreTextLayoutFrame,相当于CTFramesetter和CTFrame的关系,做的事很简单,就是通过NSAttributeString生成CTFramesetter,再根据不同的rect生成DTCoreTextLayoutFrame,并缓存这些frame。
DTCoreTextLayoutFrame
DTCoreTextLayoutFrame是最重要的一个类,负责渲染文字,主要做了两件事:生成行和渲染每一行。
生成DTCoreTextLayoutLine
-_buildLinesWithTypesetter:会创建出当前frame范围内可见的每一行DTCoreTextLayoutLine,创建过程中做的处理包括:
1.支持整段缩进
从NSAttributeString里取出当前行是否有表示缩进的DTTextBlock,如果需要缩进,要计算出当前行缩进后的宽度和位置。
2.支持截断加省略号
上层像Label/TextView这样的控件是限制了宽高的,如果内容超出了宽高,就需要对最后一行进行处理,在合适的位置加”…”。
这里有个问题,就是必须在渲染到超出宽高的那一行时,才知道要处理的最后一行是什么。例如一个TextView高40,文字每行高15,在渲染第三行时高已经到45,发现已经超出了TextView的高度,这时知道只能渲染到第二行,但当前已经处理到第三行了,需要把第二行拿出来截断加”…”。
另外除了超出高度,在超出外部传进来的numberOfLines时也要截断,为了统一流程,这里的做法是在渲染超出高度时记录总共可以渲染多少行(_numberLinesFitInFrame),然后全部重新来,从头到尾再生成每一行,这时已经知道总共有多少行,在生成最后一行时处理就行了。这样做优点是简单粗暴避免重复代码,缺点是浪费性能,前面所有行都要重新排一遍。
3.支持hyphen
hyphen是连字符号,就是让英文单词在合适的位置换行并加上破折号”-“。CoreText原生不支持hyphen,断行方式只有按单词断行和安字母断行。这里hyphen的实现方式是:在所有英文单词里可以加破折号的位置全部加上占位符0x00AD,例如location->lo-ca-tion->lo0x00ADca0x00ADtion。0x00AD是不可见字符,CoreText不会渲染这个字符,但在这个字符的位置是可以断行的,CoreText不再认为location是一个单词,会在占位符处换行。DTCoreText做的处理就是如果发现换行处是占位符0x00AD,就替换成破折号”-“,所以要支持hyphen,传进来的内容就必须是所有单词都写好占位符的,否则无效。
4.计算每一行在当前frame的位置
在生成每一行时是不知道这一行在当前frame的位置的,需要自己手动计算。每一行的x坐标容易确定,但y坐标的计算就要费一番功夫。要考虑的因素有当前行高,上一行位置,行距,段间距,padding,baseline等。

如图,每一行以baseline为基准,需要计算出这一行的baseline在当前frame的Y坐标值,asent与descent是CoreText给出的值,asent+descent就是行高。推算当前行baseline位置的流程是:
- A.计算上一行的行末位置,即baseline+descent
- B.计算上一行行间距的一半,例如1.5倍行间距,就是 ((1.5 – 1)*asent+descent)/2
- C.计算当前行行间距的一半,算法同上,只是这一行的行间距不一定与上一行一致。这里两行各算一半也是为了不同行间距的中和。
- D.上述计算结果相加,再加上当前行asent值,就得到当前行的baseline Y坐标值。
除了上述主流程,还针对首行,段首段尾,DTTextBlock的留白和附件Attachment做了处理,计算的逻辑在-_algorithmWebKit_BaselineOriginToPositionLine。
5.处理对齐
要对每一种对齐方式进行处理,右对齐和居中对齐需要计算出行的x坐标值,两端对齐需要通过CTLineCreateJustifiedLine方法重新创建出一个两端对齐的行,针对两端对齐这里还要了两件事,一是段末不做两端对齐,二是若内容长度不够(默认是不足行宽的60%)也不做两端对齐,避免文字间距拉伸得太厉害效果差。
6.封装成DTCoreTextLayoutLine
经过上述处理,每一行的CTLine对象以及这一行的位置信息都有了,把这些封装成DTCoreTextLayoutLine保存起来,任务就完成了。
渲染
DTCoreTextLayoutFrame对外提供了-drawInContext:options:方法,用于把上述生成的每一行都渲染到传进来的context画布上。做的处理包括:
1.绘制DTTextBlock样式
DTCoreText支持段落加背景色,在这里会先找出所有DTTextBlock,通过一系列麻烦的方法取到这些block的坐标和大小,把它们对应的背景色画出来。
2.绘制附件
实现了DTTextAttachmentDrawing接口的附件可以在这里跟文字一起绘制出来,在DTCoreText里图片附件就是实现了DTTextAttachmentDrawing接口,可以直接把图片在这里绘制出来。实际上图片附件的渲染DTCoreText提供了两种方式,上面介绍DTAttributedTextContentView时说图片附件也可以在上层让用户自行添加,若要在上层自行添加,可以传参数告诉DTCoreTextLayoutFrame绘制时不要处理图片附件。
3.绘制文字和阴影
最后就是再遍历每一行DTCoreTextLayoutLine以及行里的每一个DTCoreTextGlyphRun,调用它的-drawInContext:方法逐个run绘制到画布上。绘制时需要算好每个Run的位置,调用CGContextSetTextPosition定位到指定位置绘制文字。绘制文字同时还处理了阴影效果,CoreText不直接支持文字阴影效果,但可以用CoreGraphic的接口在绘制时加上阴影,这里还支持同时存在多个shadow -_-!
DTCoreTextLayoutLine
DTCoreTextLayoutLine封装了CTLine,做的事包括:
1.生成GlyphRun
通过CTLine可以取出所这一行里的CTRun,计算每个CTRun的位置,封装生成DTCoreTextGlyphRun。
2.计算属性和提供辅助方法
计算并保存了这一行asent/descent/lineHeight等属性,提供各种辅助方法方便获取这一行里的信息,包括通过stringIndex获取对应文字的坐标等,CTLine相关的几个方法例如CTLineGetOffsetForStringIndex() / CTLineGetStringIndexForPosition()也有相应的封装。
DTCoreTextGlyphRun
DTCoreTextGlyphRun里做的事跟DTCoreTextLayoutLine差不多,只是在渲染方法里额外做了一些事,首先支持文字背景色,这是CoreText原生不支持的,如果Attribute里有背景色的属性,这里会绘制出来。然后支持iOS6以下文字的下划线和删除线,iOS6以前CoreText是不支持下划线和删除线的,这里自己做了处理把它画上去。
总结
整个流程最核心的就是DTCoreTextLayoutFrame生成行和渲染的实现,相当于把CoreText原生的CTFramesetterCreateFrame / CTFrameDraw再自己实现了一遍,在实现的过程加上自己特殊的需求,从中我们也可以大致了解到CTFrame/CTLine内部大致实现是怎样的。CoreText已经提供了足够细粒度的接口让使用者可以按自己意愿去随意排版,DTCoreText这一系列的处理给出了很好的示例可供参考。